1. MapReude의 개념
Hadoop은 HDFS와 MapReduce로 구성되며, MapReduce는 HDFS에 저장된 파일을 분산 배치 분석을 할 수 있게 도와주는 프레임워크이다. MapReduce 프로그래밍 모델은 Map과 Reduce라는 두 가지 단계로 데이터를 처리한다. Map은 입력 파일을 한 줄씩 읽어서 데이터를 변형(transformation)하며, Reduce는 Map의 결과 데이터를 집계(aggregation)한다.
다음은 MapReduce 문서의 단어를 카운트하는 예제이다.

위 예제의 입력 데이터는 다음과 같다.
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad
최종 결과는 다음과 같다.
bad 1
Class 1
good 1
Hadoop 3
is 2
to 1
Welcome 1
1.1 Input splits
MapReduce의 입력은 각 Map에서 사용되는 입력 chunk인 input splits라고 불리는 고정된 크기로 나뉜다. 위의 예제를 보면 3단어씩 나뉜 것을 볼 수 있다.
1.2 Mapping
Mapping은 MapReduce 프로그램의 첫 단계이다. 이 단계에서 각 split 데이터는 Mapping 함수로 전달되고, 이후 출력 값을 생성한다. 위 예시의 Mapping 단계의 작업은 각 split에서 단어의 발생 횟수를 세고 <단어, 빈도> 형식으로 list를 생성하는 것이다.
1.3 Shuffling
Shuffling은 Mapping 단계에서 생성된 list를 통합하는 작업을 수행한다. 위 예시에서는 동일한 단어가 각각의 빈도와 함께 통합된 것을 확인할 수 있다.
1.4 Reducer
Reducer는 Shuffling에서 통합된 데이터를 집계하는 작업을 수행한다. 다시 말해, Shuffling 단계의 값을 결합하고 단일화된 출력 값을 반환한다. 위 예시에서는 각 단어의 총 발생 횟수를 계산한다.
2. MapReude Architecture
2.1 시스템 구성
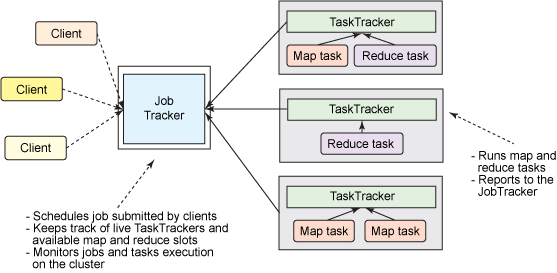
MapReduce의 시스템은 Client, JobTracker, TaskTracker로 구성된다. 다음은 MapReduce의 시스템 구성을 나타낸 것이다.
Client
Client는 사용자가 실행한 MapReduce 프로그램과 Hadoop에서 제공하는 MapReduce API를 의미한다. 사용자는 MapReduce API를 사용하여 프로그램을 개발하고, 이를 Hadoop에서 실행할 수 있다.
JobTracker
Client가 Hadoop으로 실행을 요청하는 MapReduce 프로그램은 job이라는 하나의 작업 단위로 관리된다. JobTracker는 Hadoop 클러스터에 등록된 전체 Job의 스케쥴링을 관리하고 모니터링 한다. 전체 Hadoop 클러스터에서 하나의 JobTracker가 실행되며, 보통 Hadoop의 네임노드 서버에서 실행된다.
사용자가 새로운 Job을 요청하면 JobTracker는 Job을 어떻게 처리할 것인지 계획을(Map과 Reduce를 몇개를 실행할지, 어떤 TaskTracker에 할당할 것이지) 세우고, 이를 수행한다. 이후 JobTracker와 TaskTracker는 하트비트라는 메서드로 네트워크 통신을 하면서 TaskTracker의 상태와 작업 실행 정보를 주고받게 된다. 만약 TaskTracker에 문제가 발생하면 다른 대기 중인 TaskTracker를 찾아 태스크를 재실행한다.
TaskTracker
TaskTracker는 사용자가 설정한 MapReduce 프로그램을 실행하며, Hadoop의 데이터노드에서 실행되는 데몬이다. TaskTracker는 JobTracker의 작업을 요청받고, 요청 받은 Map과 Reduce 개수만큼 Map task와 Reduce task를 생성한다. 이후 새로운 JVM을 구동해 task들을 실행한다.
2.2 데이터 플로우
이번 절에서는 앞서 MapReduce의 예시를 설명할 때 간단하게 언급했던 데이터 플로우를 자세히 다루겠다.
InputSplit and Mapping
- MapReduce는 HDFS에 저장된 파일을 읽어서 배치 처리를 수행한다. 이때 HDFS에 저장된 데이터는 대부분 큰 규모의 데이터일 것이다. MapReduce는 프레임워크는 이러한 대용량 파일을 처리하기 위해 입력 데이터 파일을 InputSplit이라는 고정된 크기의 조각으로 분리한다(분리되는 기준은 Hadoop 설정 과정에서 지정한 블록 크기로 분리된다). 이때 HDFS에 저장된 블록이 실제로 다시 분리되는 것이 아니라 가상으로 블록을 분리하는 것이다. 이처럼 InputSplit을 생성하는 과정을 split한다고 하며, InputSplit별로 하나의 Map task가 생성된다. 마지막으로 InputSplit은 Map task의 입력으로 전달된다.
- Map task는 InputSplit의 데이터를 레코드 단위로, 즉 한 줄씩 읽어서 사용자가 정의한 맵 함수를 실행한다. 이때 Map task의 출력 데이터는 TaskTracker가 실행되는 서버의 로컬 디스크에 저장되며(이게 속도 저하의 주범… 그래서 Spark이 나왔지요~), Map의 출력키를 기준으로 정렬된다. HDFS에 저장되지 않는 이유는 영구적으로 저장할 필요가 없기 때문이며, 모든 연산이 종료되면 삭제된다.
Shuffling
Map task의 출력 데이터는 중간 데이터이며, Reduce task는 이를 내려받아 연산을 수행하는데, 이때 Reduce task가 이러한 연산을 수행할 수 있게 도와주는 것이 Shuffling이다. Shuffling은 Map task의 데이터가 Reduce task에 전달되는 일련의 과정을 의미한다.
- 파티셔너는 Map의 출력 레코드를 읽어서 출력키의 해시값을 구한다. 각 해시값은 레코드가 속하는 파티션 번호로 사용된다. 파티션은 실행될 Reduce task 개수만큼 생성된다.
- 파티셔닝된 map의 출력 데이터는 네트워크를 통해 Reduce task에 전달된다. 하지만 모든 맵의 출력이 동시에 완료되지 않기 때문에 Reduce task는 자신이 처리할 데이터가 모일 때까지 대기한다. Reduce task는 Map의 출력 데이터가 모두 모이면 데이터를 정렬하고 하나의 입력 데이터로 병합나다.
- Reduce task는 병합된 데이터를 레코드 단위로 읽어 들인다.
Reducer
- Reduce task는 사용자가 정의한 Reduce 함수를 레코드 단위로 실행한다. 이때 task가 읽어 들이는 데이터는 입력키와 입력키에 해당하는 입력값의 목록으로 구성된다.
- Reduce 함수가 출력 데이터는 HDFS에 저장된다. HDFS에 Reduce 개수만큼 출력 파일이 생성되며, 파일 명은 part-nnnn으로 설정된다. 여기서 nnnn은 00000부터 1씩 증가한다.
'Data engineering > Apache Hadoop' 카테고리의 다른 글
| HDFS(Hadoop Distributed File System) (0) | 2023.03.24 |
|---|---|
| Apache Hadoop1 설치 (0) | 2023.03.24 |
| Apache Hadoop 개요 (0) | 2023.03.20 |

